Nhà máy Intel Việt Nam có Tổng giám đốc mới là ông Kenneth Tse, từng có kinh nghiệm 28 năm tại Intel.
Tập đoàn Intel vừa công bố ông Kenneth Tse đảm nhận vị trí Tổng giám đốc nhà máy Intel Việt Nam.
Ông Kenneth Tse – Tổng giám đốc nhà máy Intel Việt Nam.
Trên cương vị mới, ông Kenneth Tse chịu trách nhiệm giám sát toàn bộ hoạt động của nhà máy lắp ráp và kiểm định Intel Việt Nam, bao gồm xây dựng các mối quan hệ đối tác chiến lược với chính phủ, cộng đồng, cũng như hợp tác với hệ sinh thái địa phương.
Tổng giám đốc nhà máy Intel Việt Nam nhận định “Việt Nam là quốc gia quan trọng trong bức tranh công nghệ toàn cầu”, đồng thời nhấn mạnh “nhà máy Việt Nam luôn là nền tảng vững chắc cho quy trình vận hành của chúng tôi và tôi cam kết sẽ duy trì vị thế phát triển này”.
Ông Kenneth Tse có 28 năm làm việc tại Tập đoàn Intel. Ông bắt đầu sự nghiệp ở Intel trong vai trò Kỹ sư Quy trình tại Albuquerque, Hoa Kỳ. Sau đó, ông cũng đảm nhiệm nhiều vị trí quản lý tại thị trường Mỹ và Trung Quốc trước khi chuyển đến công tác tại Việt Nam và làm việc tại đây trong suốt một thập kỷ qua. Kenneth tốt nghiệp bằng Cử nhân Khoa học, ngành Kỹ Sư Hóa học từ Đại học California, Davis.
Trước đó, chịu trách nhiệm chính ở nhà máy Intel Việt Nam là ông Kim Huat Ooi – Phó chủ tịch phụ trách sản xuất, chuỗi cung ứng và vận hành kiêm tổng giám đốc Công ty Intel Products Việt Nam.
Nhà máy Intel Việt Nam đặt bên trong Khu công nghệ cao (TP. Thủ Đức, TP.HCM). Đây là nhà máy lắp ráp và kiểm định chip của Intel với diện tích 46.000 mét vuông, được khởi công vào tháng 3 năm 2007 và bắt đầu đi vào hoạt động từ tháng 10 năm 2010. Ở thời điểm 2023, nhà máy tạo công ăn việc làm cho khoảng 3.000 lao động và tạo việc làm gián tiếp khoảng 4.000 lao động.
Chính phủ Mỹ được cho là đã thu hồi giấy phép bán chip của Qualcomm và Intel cho Huawei, theo một báo cáo mới từ Reuters hôm nay. Mặc dù Bộ Thương mại Hoa Kỳ đã đưa ra một tuyên bố cho biết họ “đã thu hồi một số giấy phép xuất khẩu cho Huawei”, nhưng họ không nêu tên.
Tuy nhiên, nếu báo cáo ngày hôm nay là chính xác, điều đó rất có thể có nghĩa là Huawei sẽ không thể sử dụng chip từ Qualcomm hoặc Intel trong tương lai, điều này về cơ bản sẽ đảm bảo rằng họ không thể sản xuất thêm bất kỳ máy tính xách tay nào nữa, trừ khi có một số giải pháp thay thế.
Huawei MateBook X Pro 2024
Việc thu hồi giấy phép rõ ràng có hiệu lực ngay lập tức, điều này đặt ra câu hỏi có bao nhiêu máy tính xách tay MateBook X Pro được công bố gần đây mà công ty Trung Quốc có thể bán (điều này phụ thuộc vào số lượng chip Intel mà họ đã sở hữu, vì sẽ không có nhiều hơn nữa).
Qualcomm, Intel và Huawei vẫn chưa phản hồi bình luận, nhưng đây là một câu chuyện đang phát triển nên có thể thay đổi trong vài giờ hoặc vài ngày tới.
Tai ương của Huawei bắt đầu từ năm 2019, khi hãng này bị Mỹ đưa vào danh sách hạn chế thương mại, một động thái được cho là do lo ngại hãng có thể do thám người Mỹ. Sau động thái đó, các nhà cung cấp của Huawei đã phải tìm kiếm một giấy phép đặc biệt và được cho là khó xin được giấy phép trước khi xuất xưởng – và những giấy phép đó hiện đã bị thu hồi đối với Qualcomm và Intel.
Hai công ty này đã nhận được giấy phép tương ứng vào năm 2020, nhưng Qualcomm chỉ có thể bán chip 4G cũ hơn cho Huawei. Tuy nhiên, Huawei vẫn trả tiền cho Qualcomm để cấp phép cho danh mục công nghệ 5G của mình, một phần của thỏa thuận bằng sáng chế sẽ hết hạn vào năm tài chính 2025 của Qualcomm. Không rõ liệu một phần số tiền đó có được sử dụng để phát triển chip Cortex mới nhất của Huawei cho điện thoại thông minh hay không.
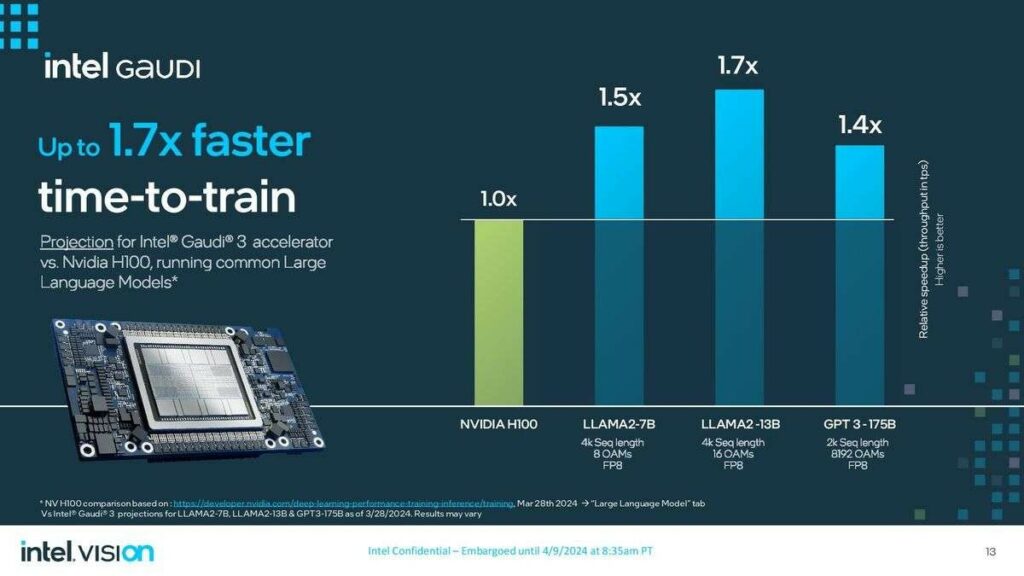
Intel đã khởi động hội nghị Vision 2024 với việc ra mắt chip xử lý AI Gaudi 3. Gaudi 3 được thiết kế để tăng tốc khối lượng công việc AI ở cấp doanh nghiệp và Intel cho rằng nó nhanh hơn tiêu chuẩn ngành hiện tại – GPU H100 của Nvidia.
Gaudi 3 sử dụng kiến trúc và nguyên tắc cơ bản giống như Gaudi 2, nhưng nó sử dụng quy trình 5nm của TSMC (so với 7nm của TSMC trong Gaudi 2), giúp hiệu quả hơn.
Gaudi 3 có tới 128GB HBM2e với băng thông 3,7 TB/s và TDP 900W.
Intel đã đưa ra các điểm chuẩn so sánh Gaudi 3 với Nvidia dẫn đầu thị trường và GPU H100 thống trị của nó, chạy các mô hình ngôn ngữ lớn khác nhau như LLAMA2-7B, LLAMA2-13B và GPT 3-175B. Gaudi 3 nhanh hơn tới 1,7 lần.
Công ty cũng cho biết Gaudi 3 có hiệu suất sử dụng điện cao hơn tới 2,3 lần so với H100 của Nvidia.
Hãng đã gửi mẫu Gaudi 3 làm mát bằng không khí để lấy mẫu cho các đối tác có sẵn rộng rãi trong Quý 3. Các thiết bị làm mát bằng chất lỏng sẽ xuất hiện vào Q4 năm nay.
Intel có thể đã sẵn sàng bổ sung vào dòng bộ xử lý tốt nhất của mình một CPU cực kỳ “khủng”. Một hình ảnh rò rỉ mới về Core i9-14900KS được đồn đại cho chúng ta biết rằng thời điểm ra mắt của nó có thể không còn xa nữa và theo báo cáo, con chip này được cho là có thể đạt tốc độ 6,2GHz ngay khi xuất xưởng.
Bức ảnh được HXL (9550pro) đăng tải vào sáng sớm hôm nay. HXL là chuyên gia rò rỉ khá nổi tiếng khi nói về CPU nhưng ngay cả người đăng ảnh cũng không chắc chắn liệu hình ảnh đó có phải là giả hay không. Ngay cả khi nó là sự thật thì họ cũng không chắc liệu Intel có ra mắt CPU này hay không. Mặc dù hình ảnh trông khá chân thực nhưng có một số điểm không nhất quán nhỏ trong chữ viết trên tản nhiệt giữa Core i9-14900KS và Core i9-13900KS.
Chúng tôi đã nghe tin đồn về sự tồn tại của Core i9-14900KS ngay từ tháng 11 năm ngoái và đến nay thông tin có vẻ khá chuẩn xác dù có vài thông số không nhất quán. Vì chúng tôi không chắc liệu Core i9-14900KS có thật hay không nên không có gì ngạc nhiên khi thông số kỹ thuật của nó vẫn chưa được xác nhận. Tuy nhiên, có tin đồn rằng sản phẩm mới có số lượng lõi tương tự như Core i9-14900K, với 24 lõi (8 lõi hiệu suất và 16 lõi hiệu suất) và 32 luồng, tốc độ xung nhịp tăng lên con số khổng lồ là 6,2 GHz. Cũng có khả năng Intel có thể tăng TDP lên 150 watt, cao hơn 25 watt so với bất kỳ chip nào khác trong bản làm mới Raptor Lake.
CPU này sẽ có giá bao nhiêu nếu nó được tung ra thị trường? Khoảng từ 600 USD đến 750 USD có vẻ là một lựa chọn an toàn. Có thể Intel sẽ công bố Core i9-14900KS tại CES 2024, vì vậy hãy chú ý theo dõi vì chúng tôi sẽ báo cáo về tất cả các bản phát hành mới.
Học liên kết hay Federated Learning trở thành một chìa khóa quan trọng để huấn luyện AI nhằm phục vụ trong mảng y tế để tạo nên được một AI hoàn chỉnh, có thể sử dụng trong nhiều tình huống mà vẫn đảm bảo hạn chế nguy cơ lộ nhiều dữ liệu cá nhân của bệnh nhân.
Y tế hiện đại ngày càng thông minh hơn nhờ áp dụng công nghệ Trí tuệ Nhân tạo (AI), trong đó mô hình học máy (Machine Learning – ML) “học” cách ra quyết định căn cứ trên bản mẫu thu thập được từ tập hợp quy mô lớn các dữ liệu của bệnh nhân. Điều đó giúp cải thiện độ chính xác trong chẩn đoán y khoa, đồng thời đẩy nhanh tốc độ nghiên cứu và phát triển nhiều phương thuốc cấp thiết.
Federated_Learning_Collaboration_Figure
Dù vậy, trong những năm gần đây các chuyên gia phát hiện rằng quy trình phát triển ứng dụng học máy truyền thống qua bộ dữ liệu tập trung hoá vẫn còn nhiều thiếu sót, bởi lẽ các mô hình ML cho chăm sóc sức khoẻ yêu cầu lượng dữ liệu nhiều hơn những gì có thể chia sẻ công khai, vốn bị giới hạn bởi vấn đề bảo mật và quyền riêng tư.
Những thách thức này đã và đang cản trở AI đưa ngành y tế lên một tầm cao mới, nơi các mô hình ML chỉ có thể đạt được độ chính xác cấp độ lâm sàng nếu được trích xuất từ các bộ dữ liệu đủ lớn, đủ đa dạng và được giám sát, biên tập kỹ lưỡng.
Nhằm dân chủ hoá AI và hưởng lợi từ dữ liệu trong chăm sóc sức khoẻ, cần xây dựng một phương pháp huấn luyện các mô hình ML không bị ảnh hưởng từ nguy cơ trong việc chia sẻ dữ liệu nhạy cảm bên ngoài cơ sở lưu trữ. Học liên kết (federated learning) là chìa khoá mở ra phương pháp đó.
Học tập tập trung không còn mang tính bền vững trong y tế
Học tập tập trung vốn là quy chuẩn truyền thống lâu nay trong mô hình hoá AI. Phương thức này yêu cầu thu thập bộ dữ liệu từ nhiều thiết bị và địa điểm, sau đó chuyển dữ liệu đến một địa điểm tập trung để thực hiện huấn luyện mô hình ML.
Điều này phát sinh không ít nguy cơ. Đầu tiên, dữ liệu được lưu trữ tập trung có thể bị đánh cắp và phơi bày, khiến cơ sở lưu trữ chịu trách nhiệm pháp lý rất lớn. Nguy cơ kế tiếp là các chủ sở hữu dữ liệu thậm chí có thể không muốn chia sẻ dữ liệu thô. Cho dù chủ sở hữu dữ liệu nguyện ý hợp tác để huấn luyện ML, thì dữ liệu thô cũng quá nhạy cảm để có thể chia sẻ.
Các mối lo ngại về bảo mật và quyền riêng tư cũng khiến công tác triển khai ở quy mô toàn cầu gặp nhiều khó khăn, nhất là với những câu hỏi về quyền sở hữu dữ liệu, tài sản trí tuệ (IP), và tuân thủ nhiều quy định luật pháp đa dạng của các quốc gia sở tại.
Những hạn chế này khiến ngày càng ít cơ quan, tổ chức đóng góp vào công tác chia sẻ dữ liệu. Việc đó cản trở mô hình ML học từ các nguồn dữ liệu đa dạng, phong phú từ các tổ chức hay địa phương khác nhau, và hậu quả tất yếu là sẽ tạo ra nhận thức thiên kiến và không chính xác.
Học liên kết mang đến những gì?
Ý tưởng chính làm nền tảng cho học liên kết là huấn luyện một mô hình ML dựa trên dữ liệu người dùng mà không cần phải truyền tải dữ liệu đó đến bất kỳ địa điểm nào khác. Cụ thể, thay vì chuyển dữ liệu đến nơi tập huấn, chúng ta sẽ đưa quy trình tính toán đến chính cơ sở hạ tầng của cơ quan, tổ chức sở hữu dữ liệu. Tại đó, một máy chủ trung tâm sẽ chịu trách nhiệm tập hợp những kết quả, nhận thức thu thập được từ công tác tính toán, tập huấn nhiều nguồn dữ liệu.
Học liên kết thực hiện nhiều chu trình huấn luyện trên chính các thiết bị, máy móc tại chỗ, đảm bảo rằng dữ liệu của Việt Nam luôn được lưu trữ trong nước. Lợi ích của việc này là sẽ không gây tổn hại hay bộc lộ dữ liệu đang di chuyển.
Mặc dù dữ liệu vẫn được khai thác để kiến tạo nhận thức trên toàn cầu, nhưng lại luôn thuộc sự kiểm soát của người sở hữu. Những tham số mô hình thu hoạch được từ công tác huấn luyện tại chỗ chủ sở hữu dữ liệu sẽ được gửi đến một máy chủ trung tâm, và tập hợp lại để hình thành một mô hình toàn cầu mới, sau đó chia sẻ với tất cả các bên tham gia.
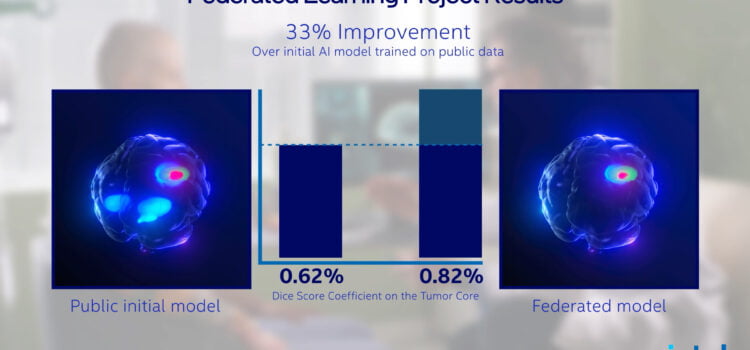
Hiện tại thì học liên kết đã gây tiếng vang bằng việc sử dụng AI tối tân để phát hiện các khối u não chính xác hơn. Từ năm 2020, Intel và Trường đại học Pennsylvania đã triển khai nghiên cứu học tập liên kết với quy mô lớn nhất ngành y tế. Sử dụng các bộ dữ liệu từ 71 cơ sở, học viện trên khắp sáu châu lục, nghiên cứu này cho thấy khả năng cải thiện phát hiện u não chính xác hơn 33%.
Để tạo dựng một nền tảng vững chắc cho học liên kết, phải bắt đầu bằng lòng tin
Đứng trước khối lượng dữ liệu khổng lồ hiện hành, điều tiên quyết là các cơ quan, tổ chức tại Việt Nam phải thiết lập được một chiến lược bảo mật dữ liệu chắc chắn và hiệu quả. Chìa khoá cho việc này chính là lưu trữ những dữ liệu nhạy cảm tại đám mây nằm trong một khu vực hạn chế truy cập, thường được gọi là Môi trường Thực thi Tin cậy (Trusted Execution Environment – TEE).
Bảo vệ quyền riêng tư là công tác thiết yếu nhằm duy trì liên tục khả năng bảo vệ khối lượng công việc kèm theo quy định của cơ quan chức năng hoặc bảo vệ dữ liệu nhạy cảm trên các mạng lưới chia sẻ chung.
Trong bối cảnh điện toán ngày càng xâm nhập vào nhiều môi trường đa dạng – từ các hệ thống sở tại cho đến đám mây công cộng và vùng biên đám mây, các cơ quan, tổ chức cần thiết lập cơ chế kiểm soát bảo mật nhằm bảo vệ tài sản trí tuệ và thông tin công việc nhạy cảm ở bất cứ nơi nào hiện đang lưu trữ dữ liệu, cũng như đảm bảo công tác làm việc từ xa cũng được thực thi với đoạn mã lệnh đã định.
Đây là lúc điện toán an toàn phát huy thế mạnh. Khác với quy trình mã hoá dữ liệu truyền thống dành cho dữ liệu ở trạng thái nghỉ hay đang được truyền tải, điện toán an toàn tận dụng TEE để tăng cường độ bảo mật và quyền riêng tư của đoạn mã lệnh sẽ được thực thi và dữ liệu đang sử dụng.
Điện toán an toàn giúp các bộ dữ liệu được xử lý an toàn hơn, và giảm thiểu nguy cơ bị tấn công bằng cách cô lập mã lệnh và dữ liệu khỏi sự xâm nhập từ bên ngoài. Là công nghệ điện toán an toàn được nghiên cứu và triển khai nhiều nhất trong các trung tâm dữ liệu hiện nay, Intel® Software Guard Extensions (Intel® SGX) cung cấp giải pháp bảo mật dựa trên phần cứng giúp bảo vệ dữ liệu đang sử dụng bằng một công nghệ cô lập ứng dụng độc đáo.
Nhờ vào nền tảng bảo mật dựa trên phần cứng, các bề mặt tấn công nhiều lỗ hổng nay đã có thể được gia cố để không chỉ bảo vệ khỏi các cuộc tấn công phần cứng, mà còn triệt tiêu những mối đe doạ đối với dữ liệu đang sử dụng. Nhờ vậy, các cơ quan, tổ chức có thể yên tâm rằng mô hình học máy của mình có thể sử dụng nhiều bộ dữ liệu khác nhau và huấn luyện thuật toán trong khi vẫn đảm bảo tuân thủ các quy định pháp luật và bảo mật hệ thống.
Tương lai của học liên kết
Bằng cách kích hoạt các mô hình ML thu thập kiến thức từ nhiều nguồn dữ liệu phong phú và đa dạng vốn không thể có được bằng những phương thức khác, học tập liên kết sở hữu tiềm năng đem đến những bước đột phá trong chăm sóc sức khoẻ, cải thiện công tác chẩn đoán, và xử lý tốt hơn vấn đề chênh lệch y tế.
Mặc dù hiện tại chúng ta mới ở bước đầu trong học liên kết, nhưng có thể nhận thấy những tiềm năng vĩ đại trong việc đưa các cơ quan, tổ chức lại gần nhau hơn nhằm chung tay hợp tác và giải quyết nhiều thách thức lớn, đồng thời vẫn giảm thiểu nguy cơ về bảo mật dữ liệu và an ninh.
Trên thực tế, học liên kết có thể mở rộng phạm vi áp dụng ra ngoài lĩnh vực chăm sóc sức khoẻ, với nhiều triển vọng lớn lao trong Internet vạn vật, công nghệ tài chính, và hơn thế nữa.Tương lai của học liên kết sẽ đưa ứng dụng AI lên một tầm cao mới, và chúng ta mới chỉ bước đầu khai thác tiềm năng thực sự của phương thức này.